In the ICLR paper [Sha22L] the authors propose a highly creative reformulation of regression that significantly outperforms standard regression with neural networks (e.g. optimizing MSE) in their experiments. Their approach can be summarized as:
- Quantizing the target $y$ into $N$ values (in a simple, uniform fashion)
- Encoding the quantized targets as binary strings of size $M$. There are $2^{M \choose N}$ possible encodings
- Instead of learning to predict the target directly, $M$ binary classifiers are trained to predict the entries of the binary code from step 2.
- At inference time, the predicted codes are decoded back to the target. For that, either the binary predictions or the predicted confidences of the $M$ classifiers can be used.
The idea is inspired by earlier work on using classifiers for ordinal regression and on using binary encodings for phrasing multiclass classification as multi-binary-classification. The procedure described above was dubbed BEL regression. It has a lot of moving parts - there are many possible encoding and decoding schemes, also the hyperparameter $N$ is important. The authors perform a theoretical and experimental analysis of various schemes and give arguments for selecting some over the other. In the end, the best performing encoding / decoding choice depends on the dataset and the networks used. These best performing combinations outperformed standard regression by a large margin! See the figure below for their comparison on several data sets.
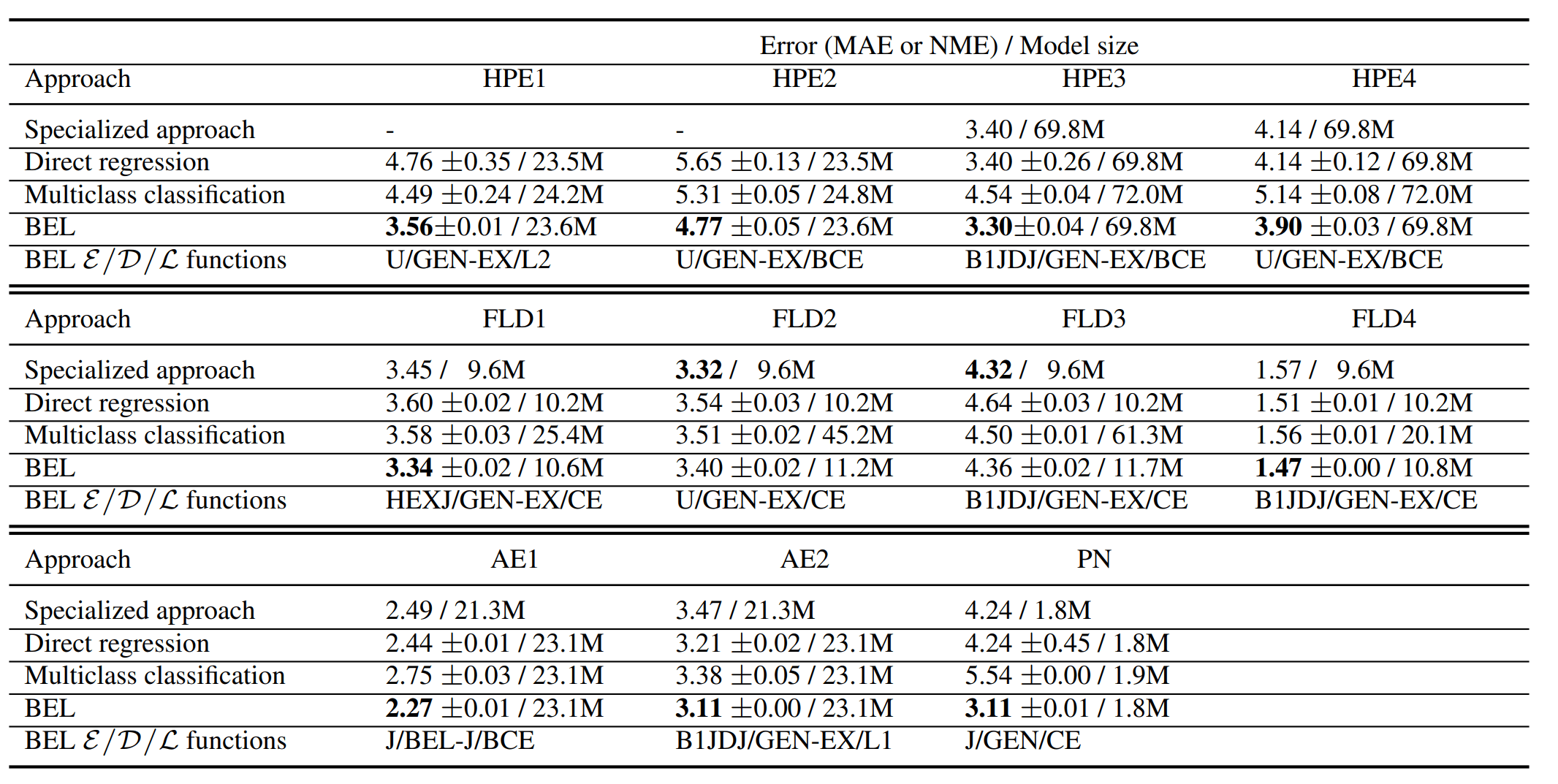
Thus, if you care a lot about having low-error neural network regression algorithms and don’t mind performing some hyperparameter search, this approach might be useful for you! The authors provide a reference implementation but for your own project you would likely need to do some implementing on your own.
This work does not compare the performance of BEL regression with non-network regressors like tree-based approaches which often outperform neural networks. Before implementing the proposed label encoding, I personally would first try something like LightGBM.
